COI360 - AI Powered Insurance Document Processing System
COI360 is a compliance management and document-processing platform used by agencies, municipalities, school districts, construction firms and enterprise risk teams to verify thousands of Certificates of Insurance each month. Accuracy is critical because verification directly affects onboarding, renewals, vendor approvals and audit readiness. This case study covers the redesign of the COI360 verification workflow. The new experience pairs adaptive AI with structured interaction design to reduce cognitive load, improve extraction reliability and help reviewers focus on high-risk areas instead of rechecking everything. My work spanned research, workflow analysis, UX and UI design, prototyping and close collaboration with engineering and compliance teams. The goal was to shift verification from manual effort to guided intelligence so accuracy and throughput could scale with rising document volume.
Role
UX Researcher
UI Designer
Year
2026
Client / Company
Management Data Inc
Problem Overview
The legacy OCR workflow struggled with real-world COIs. Low-resolution scans, handwritten entries and multi-page documents reduced extraction accuracy, leaving reviewers unable to trust the output and forcing full manual verification. The interface offered no confidence indicators, no field-to-PDF mapping, no prioritisation of risky COIs and no safeguards at final validation. Every document appeared equally important, so reviewers checked every field regardless of complexity or reliability. This resulted in heavy scrolling and searching, frequent external cleanup of poor scans, growing backlogs during peak periods and inconsistent data entering downstream compliance processes. The workflow lacked the structure and intelligence required for accuracy, speed and scale.
Solution
I redesigned the verification workflow and introduced adaptive intelligence that handles varied COI layouts, surfaces uncertainty and guides reviewers more effectively. The new experience adds confidence indicators, PDF-mapped fields, inline corrections, automatic document classification, flexible template support, mobile photo upload for higher-quality scans and a triaged queue that prioritises higher-risk COIs. Together, these improvements reduced manual effort, improved data quality and shifted verification from a fully manual process to an AI-assisted workflow.
Constraints and Challenges
Designing for a high-volume compliance platform required addressing: 1. COIs are legal documents and demand strict auditability and reliability. 2. Documents range from pristine PDFs to handwritten scans. The system needed flexibility, not fixed templates. 3. The interface had to align with grouped fields, anchors, and confidence scores. 4. Backend systems depended on older schemas, requiring careful integration. 5. Reviewers were accustomed to manual verification; the new system needed to improve efficiency without disrupting familiarity. 6. Thousands of COIs per month meant the design had to be predictable and repeatable. These constraints guided the redesign and ensured technical and operational feasibility.
Impact

How might we transform a rigid OCR based verification workflow into an AI supported, reviewer centric experience that reduces manual effort, improves accuracy and scales across diverse COI templates?

To understand why the workflow was failing, I ran a mixed method study that combined contextual inquiry and shadowing, one to one interviews, affinity mapping, persona development, journey mapping, time on task benchmarking.
The aim was to move from anecdotal complaints to structured insight that could drive design and technical decisions.
Shadowing reviewers while they worked with live COIs made the real friction visible. Observed patterns: 1. Constant scrolling through multi page PDFs to find where each extracted value came from. 2. Repeated zooming in and out to compensate for blurred scans. 3. Re-reading sections of the document multiple times. 4. Exporting unreadable PDFs to external tools for cleanup. 5. Manual re entry or correction of many extracted fields. 6. A defensive mindset where reviewers assumed the system would get things wrong. These observations showed that cognitive load, not just extraction quality, was a primary problem.
Interviews helped surface the mental model behind these behaviors. Themes that appeared repeatedly: 1. Fear of missing a detail that could create compliance exposure. 2. Frustration with doing the same checks on every COI. 3. Inability to predict how “hard” a new document would be before opening it. 4. Low trust in the OCR because there was no explanation of accuracy. 5. Desire for guidance about where to focus attention rather than a long list of fields.
I clustered all research notes into themes to distinguish systemic issues from isolated annoyances. Six core problem areas emerged:


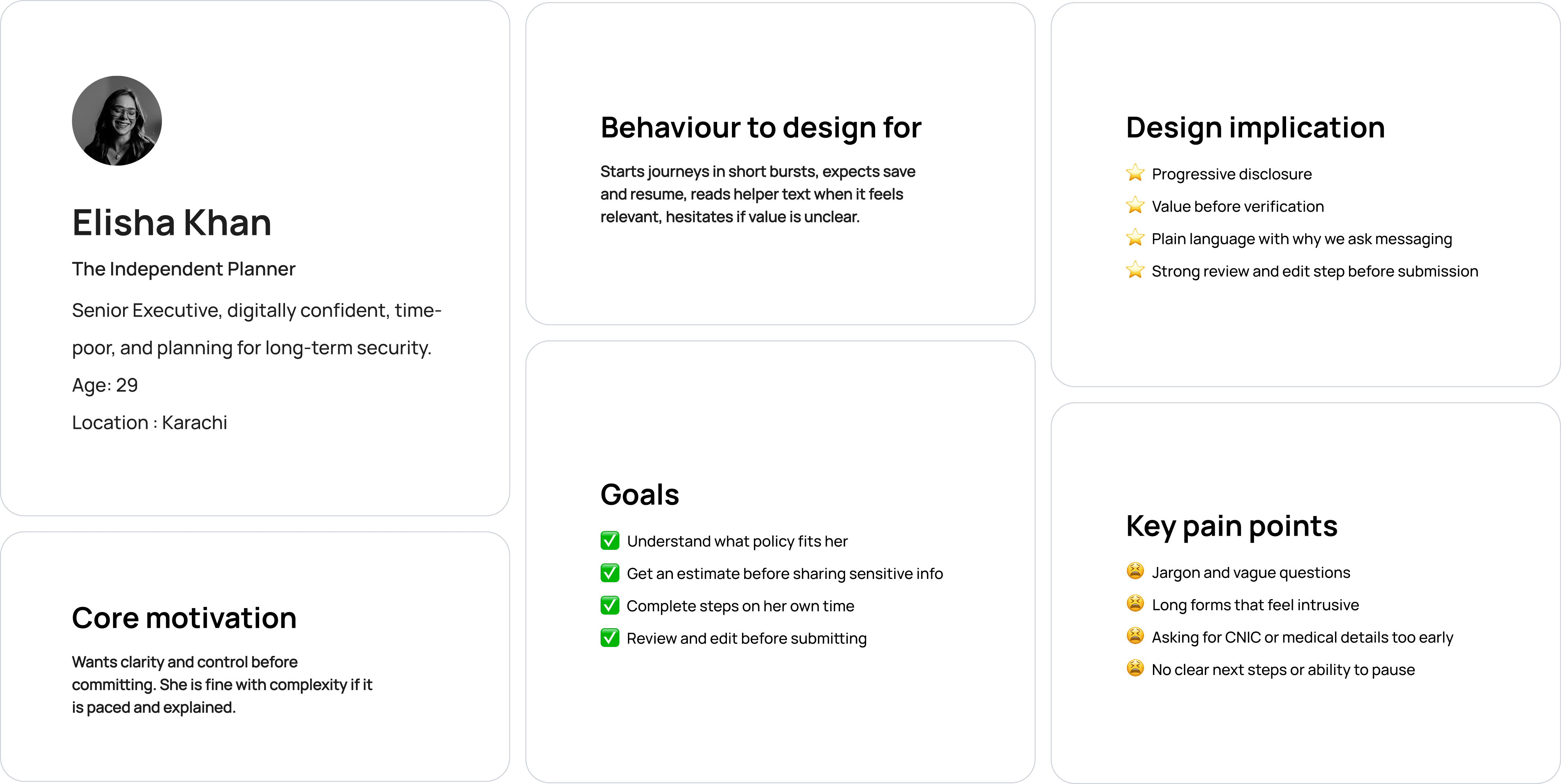
I then mapped the end to end journey of a reviewer.

To understand where reviewers were actually losing time, I ran a structured time-on-task benchmark using twenty real COIs across different levels of complexity. I observed the entire verification sequence from opening the document to submitting it and captured where effort, delays and rework occurred.
Most of the time was spent manually matching extracted values to the PDF and rechecking fields due to low trust. Reviewers repeatedly scanned pages, searched for paste targets and fixed issues caused by poor-quality scans. The data confirmed that the core problem was not OCR alone but the lack of structure, feedback and guidance within the workflow.
65%
Time spent aligning extracted data to form fields.
1-2m
Lost searching for the correct paste targets per COI.



Reviewers spent most of their time trying to answer one question: “Where did this value come from in the PDF?” The new verification screen links each extracted field to a precise region on the document. Hovering or focusing a field highlights the matching area, and selecting a region on the PDF brings the corresponding field into view. This removes the need to memorise positions, reduces scrolling and makes the connection between data and source explicit, which is critical for trust.

Non Accord 25 forms frequently failed extraction and dropped back to full manual entry. An automatic classifier detects document type at upload and selects the appropriate extraction model. The template framework is more flexible so new formats can be onboarded without large engineering changes. This reduces failures on non Accord 25 forms and future proofs the system as new forms appear.

Reviewers could edit fields before, but without confidence levels or mapping they could not tell which values were reliable, so they rechecked everything and broke flow repeatedly. Inline editing is now paired with confidence indicators and PDF-to-field mapping, allowing reviewers to correct only low confidence fields while seeing the exact source region in context. Editing becomes focused instead of repetitive, reducing unnecessary revalidation and cognitive strain while providing cleaner correction signals for model learning.

Poor scans and screenshots created noise that the models struggled with. The upload flow now supports mobile capture with basic pre processing to improve contrast and straighten the image. Improving the input quality gives the models a better chance and reduces the number of documents that reviewers need to repair in external tools.

Once the new verification flow was complete, I ran the same time-on-task study using the original twenty COIs. This allowed a direct comparison between the old and new workflows while capturing behavioural changes, efficiency gains and improvements in cognitive load.

Verification time dropped significantly as reviewers no longer needed to search for values or re-check everything manually. Confidence scoring, visual mapping and guided correction reduced mental effort and increased trust in extraction. The system auto-verified documents with predictable data, further lowering reviewer workload and reducing downstream errors.
50%
Reduction in overall verification time after redesign.
20%
Documents auto approved through confidence thresholds.
1. A portal for vendors and agents to upload, correct, and track COIs in real time. 2. Real-time compliance checks that guide users at the moment of upload. 3. A mobile capture and review experience that supports field teams. 4. Extend structured extraction to improve workflows across Renewals, Reporting, and other COI360 modules.